卷积核和通道数
每一个通道都有一个卷积核,结果值就是所有通道卷积结果的和
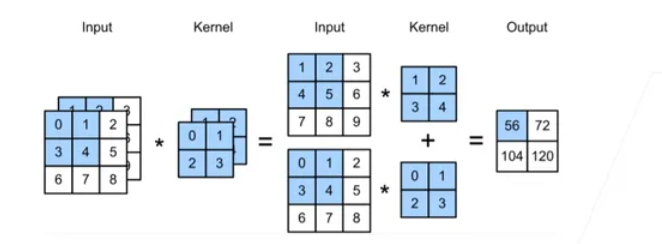
输入通道个数 等于 卷积核通道个数
卷积核个数 等于 输出通道个数
1*1的卷积核的作用
- 改变 h × w × channels 中的 channels 这一个维度的大小
- 因为1 * 1 的卷积没有进行卷积操作,相当于是对数据进行降维/升维
- 在第三个维度全连接
nn.Embedding()
1 | torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None, device=None, dtype=None) |
- num_embeddings - 词嵌入字典大小,即一个字典里要有多少个词。
- embedding_dim - 每个词嵌入向量的大小。
- padding_idx - 如果提供的话,则 padding_idx位置处的嵌入不会影响梯度,也就是训练时不会更新该索引位置的嵌入向量,默认为零向量,也可以更新为另一个值以用作填充向量
- weight (Tensor) - 形状为(num_embeddings, embedding_dim),模块中可学习的权值
1 | >>>embedding = nn.Embedding(10, 3)#构造了一个 10 * 3 的词表 ,每个词都可以用一个三维的向量表示 |
Embedding — PyTorch 2.1 documentation
nn.Conv1d
- in_channels(int) – 输入信号的通道。在文本分类中,即为词向量的维度
- out_channels(int) – 卷积产生的通道。有多少个out_channels,就需要多少个1维卷积,一个1维卷积只产生x * 1 的向量
- kernel_size(int or tuple) - 卷积核的尺寸,卷积核的大小为(k,),第二个维度是由in_channels来决定的,所以实际上卷积大小为kernel_size*in_channels
- stride(int or tuple, optional) - 卷积步长
- padding (int or tuple, optional)- 输入的每一条边补充0的层数
1 | conv1 = nn.Conv1d(in_channels=256,out_channels=100,kernel_size=2) |